Runtime environment¶
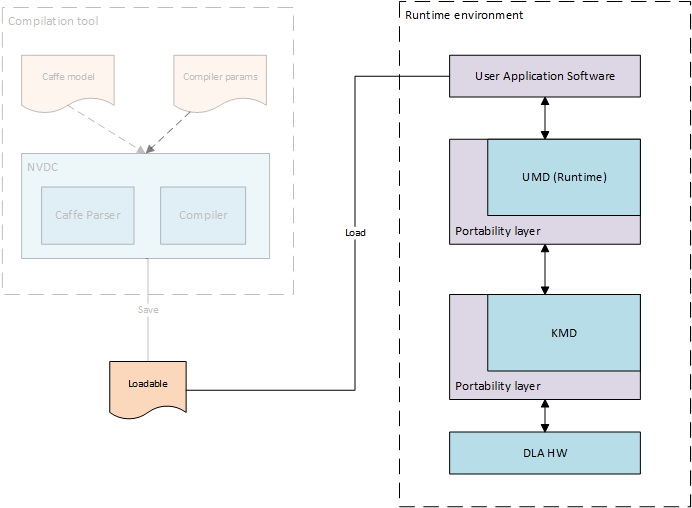
The runtime envionment includes software to run a compiled neural network on compatible NVDLA hardware. It consists of 2 parts:
User Mode Driver - This is the main interface to the application. As detailed in the Compiler library, after parsing and compiling the neural network layer by layer, the compiled output is stored in a file format called NVDLA Loadable. User mode runtime driver loads this loadable and submits inference jobs to the Kernel Mode Driver.
Kernel Mode Driver - Consists of kernel mode driver and engine scheduler that does the work of scheduling the compiled network on NVDLA and programming the NVDLA registers to configure each functional block.
The runtime environment uses the stored representation of the network saved as NVDLA Loadable image. From point of view of the NVDLA Loadable, each compiled “layer” in software is loadable on a functional block in the NVDLA implementation. Each layer includes information about its dependencies on other layers, the buffers that it uses for inputs and outputs in memory, and the specific configuration of each functional block used for its execution. Layers are linked together through a dependency graph, which the engine scheduler uses for scheduling layers. The format of an NVDLA Loadable is standardized across compiler implementations and UMD implementations. All implementations that comply with the NVDLA standard should be able to at least interpret any NVDLA Loadable image, even if the implementation may not have some features that are required to run inferencing using that loadable image.
Both the User Mode Driver stack and the Kernel Mode Driver stack exist as defined APIs, and are expected to be wrapped with a system portability layer. Maintaining core implementations within a portability layer is expected to require relatively few changes. This expedites any effort that may be necessary to run the NVDLA software-stack on multiple platforms. With the appropriate portability layers in place, the same core implementations should compile as readily on both Linux and FreeRTOS. Similarly, on “headed” implementations that have a microcontroller closely coupled to NVDLA, the existence of the portability layer makes it possible to run the same kernel mode driver on that microcontroller as would have run on the main CPU in a “headless” implementation that had no such companion microcontroller.
User Mode Driver¶
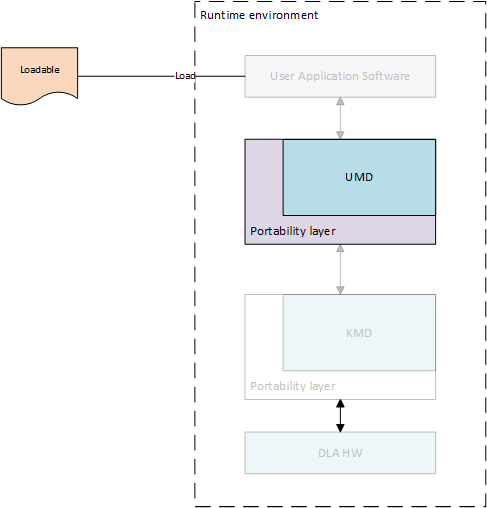
UMD provides standard Application Programming Interface (API) for processing loadable images, binding input and output tensors to memory locations, and submitting inference jobs to KMD. This layer loads the network into memory in a defined set of data structures, and passes it to the KMD in an implementation-defined fashion. On Linux, for instance, this could be an ioctl(), passing data from the user-mode driver to the kernel-mode driver; on a single-process system in which the KMD runs in the same environment as the UMD, this could be a simple function call. Low-level functions are implemented in User Mode Driver
Application Programming Interface¶
Runtime Interface¶
This is the interface for runtime library. It implements functions to process loadable buffer passed from application after reding it from file, allocate memory for tensors and intermediate buffers, prepare synchronization points and finally submit inference job to KMD. Inference job submitted to KMD is referred as DLA task.
-
class nvdla::IRuntime¶
Submitting task for inference using runtime interface includes below steps
Create NVDLA runtime instance¶
- returns:
IRuntime object
Get NVDLA device information¶
-
NvU16 nvdla::IRuntime::getMaxDevices()¶
Get maximum number of device supported by HW configuration. Runtime driver supports submitting inference jobs to multiple DLA devices. User application can select device to use. One task can’t splitted across devices but one task can be submitted to only one devices.
- Returns:
Maximum number of devices supported
-
NvU16 nvdla::IRuntime::getNumDevices()¶
Get number of available devices from the maximum number of devices supported by HW configuration.
- Returns:
Number of available devices
Load network data¶
-
NvError nvdla::IRuntime::load(const NvU8 *buf, int instance)¶
Parse loadable from buffer and update ILoadable with information required to create task
- Parameters:
buf – Loadable image buffer
instance – Device instance to load this network
- Returns:
NvError
Get input and output tensors information¶
-
NvError nvdla::IRuntime::getNumInputTensors(int *input_tensors)¶
Get number of network’s input tensors from loadable
- Parameters:
input_tensors – Pointer to update number of input tensors value
- Returns:
NvError
-
NvError nvdla::IRuntime::getInputTensorDesc(int id, NvDlaTensor *tensors)¶
Get network’s input tensor descriptor
- Parameters:
id – Tensor ID
tensors – Tensor descriptor
- Returns:
NvError
-
NvError nvdla::IRuntime::getNumOutputTensors(int *output_tensors)¶
Get number of network’s output tensors from loadable
- Parameters:
output_tensors – Pointer to update number of output tensors value
- Returns:
NvError
-
NvError nvdla::IRuntime::getOutputTensorDesc(int id, NvDlaTensor *tensors)¶
Get network’s output tensor descriptor
- Parameters:
id – Tensor ID
tensors – Tensor descriptor
- Returns:
NvError
Update input and output tensors information¶
Note
Required only if tensor information is changed, not all parameters can be changed
-
NvError nvdla::IRuntime::setInputTensorDesc(int id, const NvDlaTensor *tensors)¶
Set network’s input tensor descriptor
- Parameters:
id – Tensor ID
tensors – Tensor descriptor
- Returns:
NvError
-
NvError nvdla::IRuntime::setOutputTensorDesc(int id, const NvDlaTensor *tensors)¶
Set network’s output tensor descriptor
- Parameters:
id – Tensor ID
tensors – Tensor descriptor
- Returns:
NvError
Allocate memory for input and output tensors¶
-
NvDlaError allocateSystemMemory(void **h_mem, NvU64 size, void **pData)¶
Allocate DMA memory accessible by NVDLA for input and output tensors.
- Parameters:
h_mem – void pointer to store memory handle address
size – Size of memory to allocate
pData – Virtual address for allocated memory
- Returns:
NvError
Bind memory handle with tensor¶
-
NvError nvdla::IRuntime::bindInputTensor(int id, void *hMem)¶
Bind network’s input tensor to memory handle
- Parameters:
id – Tensor ID
hMem – DLA memory handle returned by
allocateSystemMemory()
- Returns:
NvError
-
NvError nvdla::IRuntime::bindOutputTensor(int id, void *hMem)¶
Bind network’s output tensor to memory handle
- Parameters:
id – Tensor ID
hMem – DLA memory handle returned by
allocateSystemMemory()
- Returns:
NvError
Submit task for inference¶
Unload network resources¶
-
NvError nvdla::IRuntime::unload(int instance)¶
Unload network data, free all resourced used for network if no plan to submit inference using same network
- Parameters:
instance – Device instance from where to unload
- Returns:
NvError
Portability layer¶
Portability layer for UMD implements functions to access NVDLA device, allocate DMA memory and submit task to low level driver. For this functionality UMD has to communicate with KMD and the communication interface is OS dependent. Portability layer abstracts this OS dependent interface.
-
type NvError¶
Enum for error codes
-
type NvDlaHeap¶
Memory heap to allocate memory, NVDLA supports two memory interfaces. Generally these interfaces are connected to DRAM (System memory) and internal SRAM. KMD can maintain separate heaps for allocation depending on memory type.
-
type NvDlaMemDesc¶
Memory descriptor, it includes memory handle and buffer size.
-
type NvDlaTask¶
DLA task structure. Runtime driver populates it using information from loadable and is used by portability layer to submit inference task to KMD in an implementation define manner.
-
NvError NvDlaInitialize(void **session_handle)¶
This API should initialize session for portability layer which may include allocating some structure required to maintain information such such device context, file descriptors. This function can be empty.
- Parameters:
session_handle – [out] Pointer to update session handle address. This address is passed in any APIs called after this which can be used by portability layer to recover session information.
- Returns:
-
void NvDlaDestroy(void *session_handle)¶
Release all session resources
- Parameters:
session_handle – Session handle address obtained from
NvDlaInitialize()
-
NvError NvDlaOpen(void *session_handle, NvU32 instance, void **device_handle)¶
This API should open DLA device instance. .
- Parameters:
session_handle – Session handle address obtained from
NvDlaInitialize()instance – NVDLA instance to use if there are more than one instances in SoC
device_handle – [out] Pointer to update device context. It is used to obtain device information required for further callbacks which need device context.
- Returns:
-
void NvDlaClose(void *session_handle, void *device_handle)¶
Close DLA device instance
- Parameters:
session_handle – Session handle address obtained from
NvDlaInitialize()device_handle – Device handle address obtained from
NvDlaOpen()
-
NvError NvDlaSubmit(void *session_handle, void *device_handle, NvDlaTask *tasks, NvU32 num_tasks)¶
Submit inference task to KMD
- Parameters:
session_handle – Session handle address obtained from
NvDlaInitialize()device_handle – Device handle address obtained from
NvDlaOpen()tasks – Lists of tasks to submit for inferencing
num_tasks – Number of tasks to submit
- Returns:
-
NvError NvDlaAllocMem(void *session_handle, void *device_handle, void **mem_handle, void **pData, NvU32 size, NvDlaHeap heap)¶
Allocate, pin and map DLA engine accessible memory. For example, in case of systems where DLA is behind IOMMU then this call should ensure that IOMMU mappings are created for this memory. In case of Linux, internal implementation can use readily available frameworks such as ION for this.
- Parameters:
session_handle – Session handle address obtained from
NvDlaInitialize()device_handle – Device handle address obtained from
NvDlaOpen()mem_handle – [out] Memory handle updated by this function
pData – [out] If the allocation and mapping is successful, provides a virtual address through which the memory buffer can be accessed.
size – Size of buffer to allocate
heap – Implementation defined memory heap selection
- Returns:
-
NvError NvDlaFreeMem(void *session_handle, void *device_handle, void *mem_handle, void *pData, NvU32 size)¶
Free DMA memory allocated using
NvDlaAllocMem()- Parameters:
session_handle – Session handle address obtained from
NvDlaInitialize()device_handle – Device handle address obtained from
NvDlaOpen()mem_handle – Memory handle address obtained from
NvDlaAllocMem()pData – Virtual address returned by
NvDlaAllocMem()size – Size of the buffer allocated
- Returns:
-
void NvDlaDebugPrintf(const char *format, ...)¶
Outputs a message to the debugging console, if present.
- Parameters:
format – A pointer to the format string
Kernel Mode Driver¶
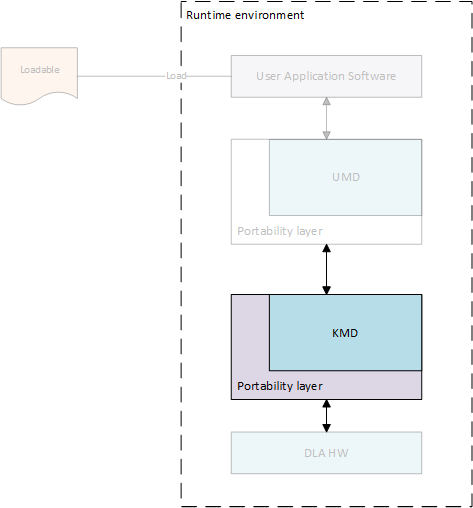
The KMD main entry point receives an inference job in memory, selects from multiple available jobs for execution (if on a multi-process system), and submits it to the core engine scheduler. This core engine scheduler is responsible for handling interrupts from NVDLA, scheduling layers on each individual functional block, and updating any dependencies based upon the completion of the layer. The scheduler uses information from the dependency graph to determine when subsequent layers are ready to be scheduled; this allows the compiler to decide scheduling of layers in an optimized way, and avoids performance differences from different implementations of the KMD.
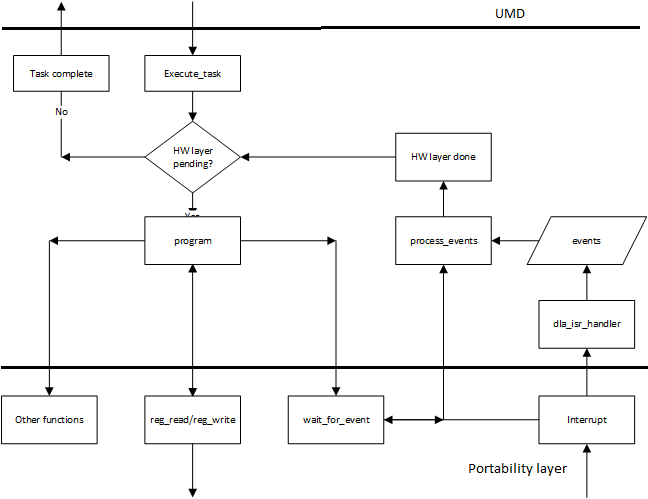
Core Engine Interface¶
Neural networks are converted to hardware layers for execution on DLA hardware. These layers are connected to each other using dependency graph and executed on DLA by module known as engine scheduler. This scheduler is responsible for updating dependency counts, handling events and programming hardware layers. It is the core module of DLA software and portable across different OS. Portability layer should use below interfaces to enable core engine module. Core engine module is also referenced as firmware as same source code would be used in firmware of companion controller for headed configs.
General sequence of execution in KMD is as below
Register driver with firmware during probe¶
-
int32_t dla_register_driver(void **engine_context, void *driver_context)¶
This function must be called once during boot to initialize DLA engine scheduler and register driver with firmware before submitting any task. Pass pointer to driver context in @param driver_context which is passed as param when firmware calls any function of portability layer. It also updates pointer to engine context which must be passed in any function call to firmware after this point.
- Parameters:
engine_context – Pointer to engine specific data
driver_context – Pointer to driver specific data
- Returns:
0 on success and negative on error
Driver submits task information for execution¶
-
type dla_task_descriptor¶
Task descriptor structure. This structure includes all the information required to execute a network such as number of layers, dependency graph address etc.
-
int32_t dla_execute_task(void *engine_context, void *task_data)¶
This function initializes sub-engines and starts task execution. Further programming and layer scheduling is triggered by events received from hardware.
- Parameters:
engine_context – Engine specific data received in
dla_register_driver()task_data – Task specific data to be passed when reading task info
- Returns:
0 on success and negative on error
Interrupt received from hardware¶
-
int32_t dla_isr_handler(void *engine_context)¶
This function is called when DLA interrupt is received. Portability layer should register it’s own handler using the mechanism supported by that platform and call this function from the handler. Call to this function must be protected by lock to prevent handling interrupt when firmware is programming layers in process context.
- Parameters:
engine_context – Engine specific data received in
dla_register_driver()
- Returns:
0 on success and negative on error
Bottom half caller to process events after interrupt¶
-
int32_t dla_process_events(void *engine_context, uint32_t *task_complete)¶
Interrupt handler just records events and does not process those events. Portability layer must call this function in thread/process context after interrupt handler is done.
- Parameters:
engine_context – Engine specific data received in
dla_register_driver()task_complete – Pointer to parameter to indicate task complete, firmare writes 1 to it if all layers are processed.
- Returns:
0 on success and negative on error
Clean task and engine state¶
-
void dla_clear_task(void *engine_context)¶
This function resets engine scheduler state including op descriptor cache, error values, sub-engine status, events etc and clears previous task state from firmware. This function can be called by portability layer after task completion. It is not mandatory to call it but calling it will ensure clean state before next task execution.
- Parameters:
engine_context – Engine specific data received in
dla_register_driver()
- Returns:
0 on success and negative on error
Portability layer¶
Core engine module (firmware) is OS independent but it still needs some OS services such as memory allocation, read/write IO registers, interrupt notifications. Portability layer implemented in KMD should provide implementation for below interfaces to core engine module.
Firmware programs hardware layer¶
-
uint32_t dla_reg_read(void *driver_context, uint32_t addr)¶
Read DLA HW register. Portability layer is responsible to use correct base address and for any IO mapping if required.
- Parameters:
driver_context – Driver specific data received in
dla_register_driver()addr – Register offset
- Returns:
Register value
-
void dla_reg_write(void *driver_context, uint32_t addr, uint32_t reg)¶
Write DLA HW registr. Portability layer is responsible to use correct base address and for any IO mapping if required.
- Parameters:
driver_context – Driver specific data received in
dla_register_driver()addr – Register offset
reg – Value to write
-
int32_t dla_read_dma_address(struct dla_task_desc *task_desc, int16_t index, void *dst)¶
Read DMA address from address list at index specified. This function is used by functional block programming operations to read address for DMA engines in functional blocks.
- Parameters:
task_desc – Task descriptor for in execution task
index – Index in address list
dst – Destination pointer to update address
- Returns:
0 in case success, error code in case of failure
-
int32_t dla_read_cpu_address(struct dla_task_desc *task_desc, int16_t index, void *dst)¶
Read CPU accessible address from address list at index specified. This function is used by engine scheduler to read data from memory buffer. Address returned by this function must be accessible by processor running engine scheduler.
- Parameters:
task_desc – Task descriptor for in execution task
index – Index in address list
dst – Destination pointer to update address
- Returns:
0 in case success, error code in case of failure
-
int32_t dla_data_read(void *driver_context, void *task_data, uint64_t src, void *dst, uint32_t size, uint64_t offset)¶
This function reads data from buffers passed by UMD in local memory. Addresses for buffers passed by are shared in address list and network descriptor contains index in address list for those buffers. Firmware reads this data from buffer shared by UMD into local buffer to consume the information.
- Parameters:
driver_context – Driver specific data received in
dla_register_driver()task_data – Task specific data received in
dla_execute_task()src – Index in address list
dst – Local memory address
size – Data size
offset – Offset from start of UMD buffer
- Returns:
0 in case success, error code in case of failure
-
int32_t dla_data_write(void *driver_context, void *task_data, void *src, uint64_t dst, uint32_t size, uint64_t offset)¶
This function writes data from local buffer to buffer passed by UMD. Addresses for buffers passed by are shared in address list and network descriptor contains index in address list for those buffers. Firmware writes this data to buffer shared by UMD from local buffer to update the information.
- Parameters:
driver_context – Driver specific data received in
dla_register_driver()task_data – Task specific data received in
dla_execute_task()src – Local memory address
dst – Index in address list
size – Data size
offset – Offset from start of UMD buffer
- Returns:
0 in case success, error code in case of failure
-
DESTINATION_PROCESSOR¶
Memory will be accessed by processor running firmware.
-
DESTINATION_DMA¶
Memory will be accessed by NVDLA DMA engines
-
int32_t dla_get_dma_address(void *driver_context, void *task_data, int16_t index, void *dst_ptr, uint32_t destination)¶
Some buffers shared by UMD are accessed by processor responsible for programming DLA HW. It would be companion micro-controller in case of headed config while main CPU in case of headless config. Also, some buffers are accessed by DLA DMA engines inside sub-engines. This function should return proper address accessible by destination user depending on config.
- Parameters:
driver_context – Driver specific data received in
dla_register_driver()task_data – Task specific data received in
dla_execute_task()index – Index in address list
dst_ptr – Pointer to update address
destination – Destination user for DMA address,
DESTINATION_PROCESSORorDESTINATION_DMA
-
int64_t dla_get_time_us(void)¶
Read system time in micro-seconds
- Returns:
Time value in micro-seconds
-
void *dla_memset(void *src, int ch, uint64_t len)¶
Fills the first len bytes of the memory area pointed to by src with the constant byte ch.
- Parameters:
src – Memory area address
ch – Byte to fill
len – Length of memory area to fill
- Returns:
Memory area address
-
void *dla_memcpy(void *dest, const void *src, uint64_t len)¶
- Parameters:
dest – Destination memory area address
src – Source memory area address
len – Length of memory area to copy
- Returns:
Destination memory area address
-
void dla_debug(const char *str, ...)¶
Print debug message to console
- Parameters:
str – Format string and variable arguments
-
void dla_info(const char *str, ...)¶
Print information message to console
- Parameters:
str – Format string and variable arguments
-
void dla_warn(const char *str, ...)¶
Print warning message to console
- Parameters:
str – Format string and variable arguments
-
void dla_error(const char *str, ...)¶
Print error message to console
- Parameters:
str – Format string and variable arguments